Machine Learning
Machine Learning Fairness: Lessons Learned
Author: Marco Liu | Published 2022-05-03 00:00:00 +0000
Nowadays, machine learning is more and more widely used in people’s daily life. For example, the recommender system is used by Amazon, Netflix and other websites to recommend the most suitable products or movies for users. [^1] However, sometimes ML may also make mistakes, which we call ML bias. In some cases, it may lead to serious consequences. For instance, courts in the United States use COMPAS, an AI algorithm for recidivism prediction to assist the judge to decide whether to release the criminal or not. However, a bias against African-Americans was found in the algorithm: COMPAS is more likely to assign African-American criminals a higher risk score than white criminals with the same profile [^2].
Addressing fairness in AI is an active area of research at Google, including training models to remove or correct problematic biases. In Google I/O’19, Tulsee, the leader of the product for ML fairness at Google, shared us with the lessons they have learned from ML fairness.
According to the video, unfairness may enter at any point of the ML pipeline (see Fig.1), from data collection and handling to model training to end use. Also, you can rarely identify a single cause of or a single solution to these problems since various causes may interact in ML systems to produce problematic outcomes, and a series of solutions is needed [^3].
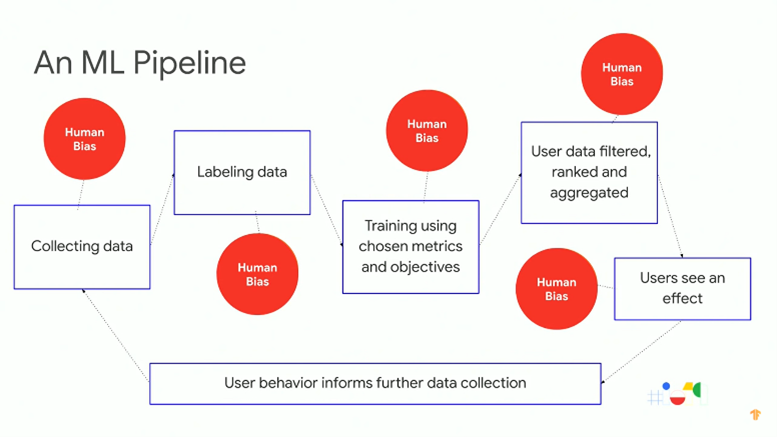
Fig.1 An ML pipeline
Normally there are three different aspects where ML bias may happen, which are data collection, measurement and modelling as well as design. First of all, datasets are critical for the ML development process. However, the training data received by the algorithm may be skewed for some social issues, which is then exacerbated by the technical implementation. Even if you have a perfectly balanced training dataset, it doesn’t necessarily imply that the output of your model will be perfectly fair, since different fairness concerns may require different metrics, even within the same product experience. Also, the representational harm problem, which refers to a model showing an offensive stereotype or harmful association, could happen sometimes. Figure 2 presents the representational harm problem of a Google API which can detect hatred and harassment in online conversations. As shown in the figure, the sentence, “I am straight,” was given a score of 0.04 and classified as “unlikely to be perceived as toxic.” Whereas the sentence, “I am gay,” was given a score of 0.86 and classified as “likely to be perceived as toxic.” Both sentences are harmless statements of identity, but one was given a significantly higher score.
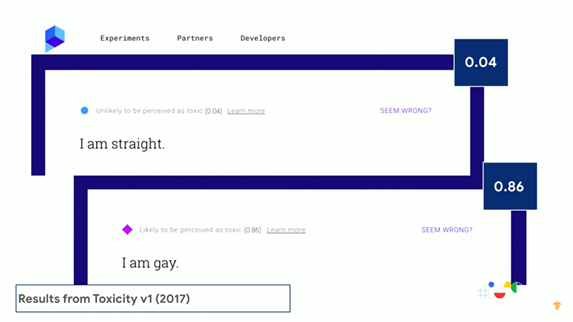
Fig.2 the representational harm problem of a Google API
Let’s talk in depth about ML bias caused by skewed data collection. Figure 3 is a vivid example of this issue, in which you’ll find the label “wedding” was only applied to the images on the left but not to the image on the right. That’s because the open-source image classifier trained on the open images dataset does not properly recognize wedding traditions from all around the world. Some open-source datasets have been found to be geographically biased according to their collection methods and locations.

Fig.3 ML bias caused by skewed data collection
Then how to solve such problems? How can we collect completely diverse datasets for our models? Since we don’t always know what we are missing from the beginning and where are our blind spots, it’s always important to test and measure these issues for various groups, so that we can identify where our model may not perform well and where we may want to consider more principled improvements. Besides, Google has released their first Data Card in Oct. 2018 as part of the Open Images Extended Dataset (see Fig.4). This Data Card can answer questions like how the data was sourced and what the distribution is. For the Open Images Extended Dataset, while you can find the geographic distribution is extremely diverse, 80% of the data comes from India. Such information is important for people who want to use this dataset for training or testing.
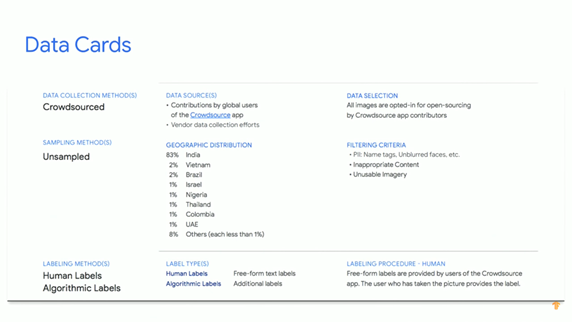
Fig.4 Google Data Card
In conclusion, it’s of great significance to reduce bias in machine learning and we are glad to see that Google keeps trying to develop fairer products that work equitably for everyone. We hope that there will be more measures devoted to ML fairness in the future.
Reference
[1] Z. Zhong, “A Tutorial on Fairness in Machine Learning,” towards data science, Oct. 22, 2018. [Online]. Available: https://towardsdatascience.com/a-tutorial-on-fairness-in-machine-learning-3ff8ba1040cb. [Accessed Apr. 29, 2021].
[2] N. Mehrabi, F. Morstatter, N. Saxena, K. Lerman and A. Galstyan, “A Survey on Bias and Fairness in Machine Learning,” arXiv, Sep. 17, 2019. [Online]. Available: https://arxiv.org/pdf/1908.09635.pdf. [Accessed Apr. 29, 2021].
[3] Machine Learning Fairness: Lessons Learned (Google I/O’19), YouTube, May 10, 2019. [Online]. Available: https://www.youtube.com/watch?v=6CwzDoE8J4M&list=PLOU2XLYxmsILVTiOlMJdo7RQS55jYhsMi&index=80. [Accessed Apr. 29, 2021].